
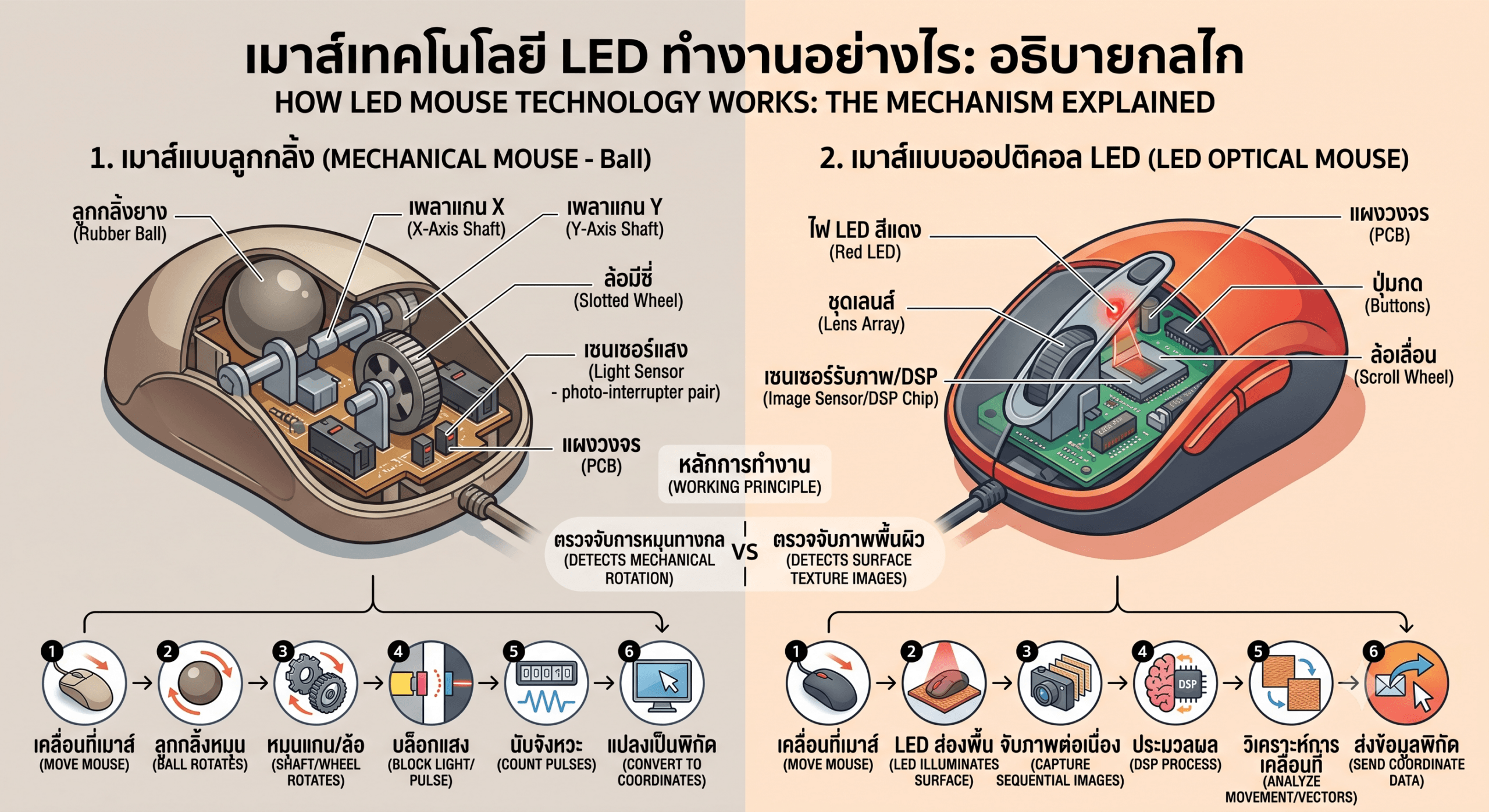
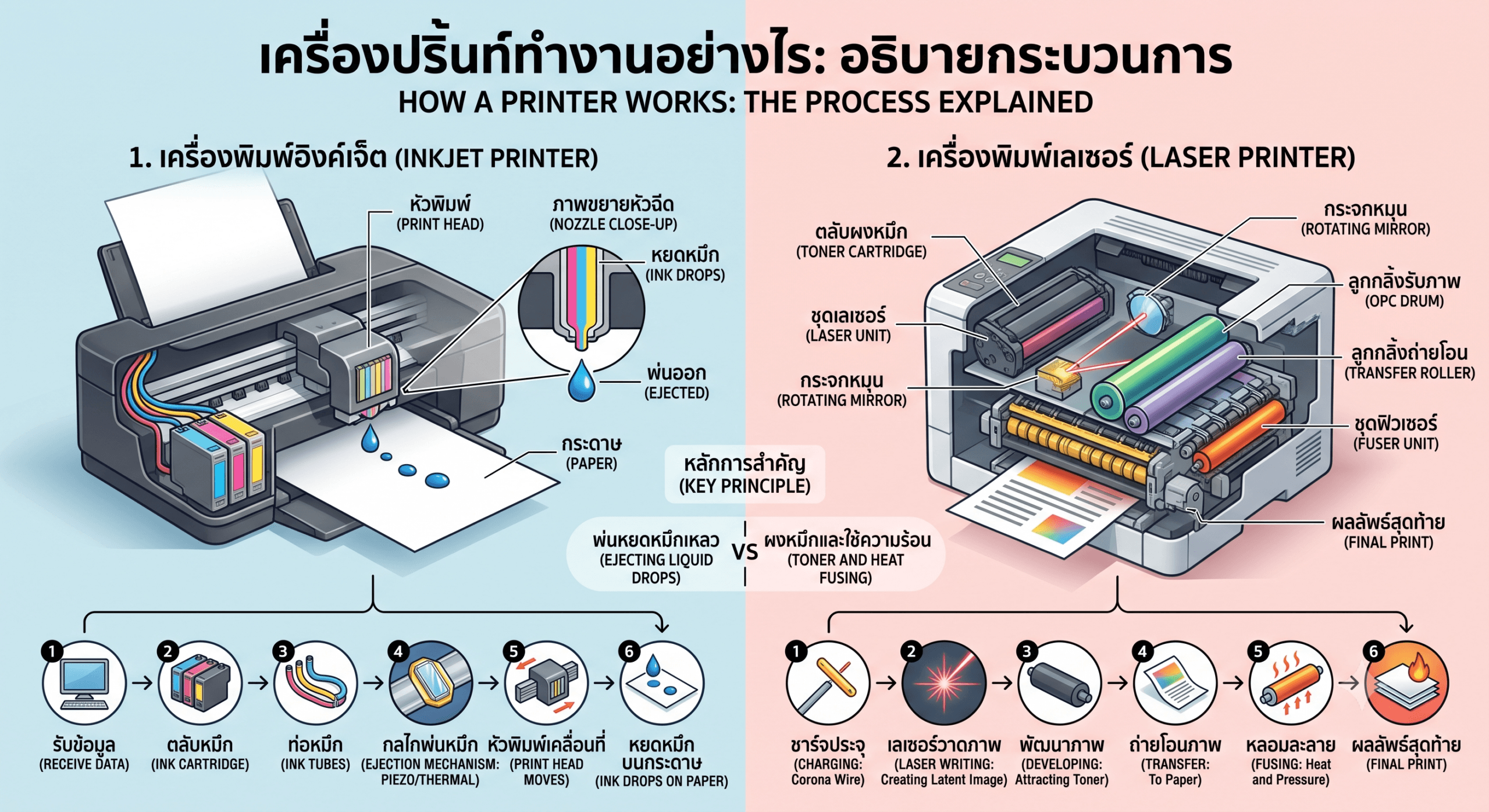
Server Cluster คืออะไร?
Server Cluster คือการรวมกลุ่มของเซิร์ฟเวอร์ (Nodes) หลายเครื่องเข้าด้วยกันเพื่อให้ทำงานร่วมกันในลักษณะเป็นระบบเดียว โดยมีจุดประสงค์หลักเพื่อ
- เพิ่มความสามารถในการประมวลผล (Performance)
- รองรับปริมาณงานที่เพิ่มขึ้น (scalability)
- ลดภาระงานที่กระจุกตัวในเซิร์ฟเวอร์เพียงเครื่องเดียว
- เพิ่มความน่าเชื่อถือ (Reliability)
- ลดความเสี่ยงที่ระบบทั้งหมดจะหยุดทำงานหากเซิร์ฟเวอร์ตัวใดตัวหนึ่งล้มเหลว
- เพิ่มความพร้อมใช้งาน (High Availability)
- รับประกันว่าแอปพลิเคชันหรือบริการยังคงทำงานต่อได้แม้จะมีความล้มเหลวของฮาร์ดแวร์หรือซอฟต์แวร์
- เพิ่มความยืดหยุ่นในการจัดการทรัพยากร (Resource Efficiency)
- รองรับการปรับเปลี่ยนและกระจายทรัพยากรเพื่อให้เหมาะสมกับปริมาณงาน
องค์ประกอบของ Server Cluster
การตั้งค่าระบบ Server Cluster จะประกอบด้วยส่วนสำคัญดังนี้
1. Nodes (เซิร์ฟเวอร์ในคลัสเตอร์)
- เป็นเซิร์ฟเวอร์แต่ละเครื่องที่รวมกันในระบบคลัสเตอร์
- อาจเป็นแบบ Physical Machines หรือ Virtual Machines (VMs)
- แต่ละ Node มีทรัพยากรเป็นของตัวเอง เช่น CPU, RAM, และ Storage
2. Cluster Management Software
- เป็นซอฟต์แวร์ที่จัดการการทำงานของคลัสเตอร์ เช่น
- ตรวจสอบสถานะ (Monitoring)
- จัดการการโยกย้ายงาน (Failover)
- กระจายโหลด (Load Balancing)
- ตัวอย่างซอฟต์แวร์ที่ใช้
- Kubernetes ใช้สำหรับจัดการ Containers
- Pacemaker/Corosync ใช้ในระบบ Linux สำหรับ High Availability
- Apache Mesos จัดการทรัพยากรในงาน Big Data และงานที่ต้องการการประมวลผลสูง
3. Shared Storage
- ใช้เป็นพื้นที่เก็บข้อมูลที่ทุก Node สามารถเข้าถึงได้ร่วมกัน เช่น
- NFS (Network File System)
- iSCSI (Internet Small Computer Systems Interface)
- Distributed File Systems เช่น GlusterFS, Ceph
- ช่วยให้ระบบสามารถทำงานต่อได้แม้ Node ใด Node หนึ่งจะล้มเหลว
4. Networking
- การสื่อสารระหว่าง Nodes ในคลัสเตอร์ต้องมีเครือข่ายที่มีความเร็วสูงและเสถียร
- ใช้เครือข่ายเฉพาะ (Private Network) สำหรับการส่งข้อมูลที่สำคัญ เช่น Heartbeat เพื่อแจ้งสถานะระหว่าง Nodes
หลักการทำงานของ Server Cluster
1. การตรวจสอบสถานะ (Monitoring and Heartbeat)
- ทุก Node ในคลัสเตอร์จะส่งสัญญาณ Heartbeat (สัญญาณการตรวจสอบ) ผ่านเครือข่ายเฉพาะไปยัง Cluster Management Software
- หาก Node ใดหยุดตอบสนอง (เช่น เกิด Hardware Failure) ระบบจะถือว่า Node นั้นล้มเหลว และเริ่มกระบวนการ Failover
2. Failover (การโยกย้ายงาน)
- กระบวนการโยกย้ายงานที่กำลังทำอยู่จาก Node ที่ล้มเหลวไปยัง Node อื่นในคลัสเตอร์
- ตัวอย่างการทำงาน
- หาก Node A ที่ให้บริการฐานข้อมูลหยุดทำงาน ระบบจะโยกย้ายฐานข้อมูลไปยัง Node B และเริ่มให้บริการต่อ
3. Load Balancing (การกระจายโหลด)
- เมื่อมีคำขอ (Requests) จำนวนมากเข้ามา เช่น จากผู้ใช้บนเว็บไซต์ ระบบจะกระจายโหลดไปยัง Nodes ที่มีอยู่ทั้งหมด
- อัลกอริทึมการกระจายโหลดที่นิยมใช้
- Round Robin กระจายคำขอแบบวนรอบ
- Least Connections กระจายงานไปยัง Node ที่มีการเชื่อมต่อน้อยที่สุด
- Weighted Load Balancing ให้ Node ที่มีทรัพยากรมากกว่าแบกรับภาระมากกว่า
4. High Availability (HA)
- มุ่งเน้นให้ระบบทำงานได้ตลอดเวลา
- ระบบจะใช้แนวคิด Redundancy โดยเก็บข้อมูลหรือกระบวนการไว้ในหลาย Node
- ตัวอย่างเช่น
- การจำลองฐานข้อมูลแบบ Active-Active Replication หรือ Active-Passive Replication
5. Scalability (การปรับขยาย)
- หากปริมาณงานเพิ่มขึ้น สามารถเพิ่ม Node ใหม่เข้าคลัสเตอร์ได้อย่างง่ายดาย
- เช่น ใน Kubernetes สามารถเพิ่ม Pods หรือ Nodes ใหม่เพื่อรองรับปริมาณงานที่สูงขึ้น
6. Distributed Processing (การประมวลผลแบบกระจาย)
- ระบบสามารถกระจายงานที่ซับซ้อนออกเป็นส่วนย่อย ๆ เพื่อให้หลาย Node ประมวลผลพร้อมกัน
- เหมาะสำหรับงานที่ต้องการพลังการประมวลผลสูง เช่น การวิเคราะห์ข้อมูล Big Data หรือ Machine Learning
ประเภทของ Server Cluster
1. High-Availability Cluster (HA Cluster)
- เน้นลด Downtime และเพิ่มความต่อเนื่องของระบบ
- ใช้ในงานที่ต้องให้บริการตลอดเวลา เช่น ฐานข้อมูล, ระบบธนาคาร
- ตัวอย่างซอฟต์แวร์ Pacemaker, Corosync
2. Load Balancing Cluster
- กระจายโหลดให้กับเซิร์ฟเวอร์หลายเครื่อง
- เหมาะสำหรับเว็บเซิร์ฟเวอร์ที่มีผู้ใช้งานจำนวนมาก
- ตัวอย่างซอฟต์แวร์ HAProxy, NGINX
3. High-Performance Computing Cluster (HPC Cluster)
- ใช้สำหรับงานที่ต้องการการประมวลผลสูง เช่น งานวิทยาศาสตร์ การวิเคราะห์ข้อมูล
- ตัวอย่างซอฟต์แวร์ SLURM, Hadoop
4. Storage Cluster
- ใช้สำหรับจัดการข้อมูลขนาดใหญ่ในหลาย Node
- ตัวอย่าง Ceph, GlusterFS
Server Cluster เป็นโซลูชันที่สำคัญในระบบ IT สมัยใหม่ โดยเฉพาะในงานที่ต้องการความเสถียร ความต่อเนื่อง และการประมวลผลที่มีประสิทธิภาพสูง